
قيود المعايير. اختبار بيرسون كاي سكوير. اختبار فرضيات بسيطة باختبار Pearson chi-square في MS EXCEL

23. مفهوم توزيع مربع كاي والطالب وعرض رسومي
1) توزيع (مربع كاي) مع n درجة من الحرية هو توزيع مجموع مربعات n من المتغيرات العشوائية القياسية المستقلة.
التوزيع (تشي - تربيع)- توزيع متغير عشوائي(و القيمة المتوقعةكل واحد منهم هو 0 ، والانحراف المعياري هو 1)
حيث المتغيرات العشوائية ![]() مستقلة ولها نفس التوزيع. في هذه الحالة ، يسمى عدد المصطلحات ، أي "عدد درجات الحرية" لتوزيع مربع كاي. يتم تحديد عدد مربع كاي بواسطة معلمة واحدة ، عدد درجات الحرية. مع زيادة عدد درجات الحرية ، يقترب التوزيع ببطء من الوضع الطبيعي.
مستقلة ولها نفس التوزيع. في هذه الحالة ، يسمى عدد المصطلحات ، أي "عدد درجات الحرية" لتوزيع مربع كاي. يتم تحديد عدد مربع كاي بواسطة معلمة واحدة ، عدد درجات الحرية. مع زيادة عدد درجات الحرية ، يقترب التوزيع ببطء من الوضع الطبيعي.
ثم مجموع مربعاتهم
هو متغير عشوائي يتم توزيعه وفقًا لما يسمى بقانون مربع كاي مع k = n درجات الحرية ؛ إذا كانت المصطلحات مرتبطة ببعض العلاقات (على سبيل المثال ،) ، فإن عدد درجات الحرية هو k = n - 1.
كثافة هذا التوزيع

هنا ![]() - وظيفة جاما ؛ على وجه الخصوص ، Г (ن + 1) = ن! .
- وظيفة جاما ؛ على وجه الخصوص ، Г (ن + 1) = ن! .
لذلك ، يتم تحديد توزيع مربع كاي بمعامل واحد - عدد درجات الحرية ك.
ملاحظة 1. مع زيادة عدد درجات الحرية ، يقترب توزيع مربع كاي تدريجياً من الوضع الطبيعي.
ملاحظة 2. باستخدام توزيع "chi-square" ، يتم تحديد العديد من التوزيعات الأخرى التي يتم مواجهتها في الممارسة ، على سبيل المثال ، توزيع متغير عشوائي - طول المتجه العشوائي (X1، X2، ...، Xp) ، إحداثياتها مستقلة وموزعة وفق القانون العادي.
تم النظر في توزيع χ2 لأول مرة بواسطة R.Helmert (1876) و K. Pearson (1900).
Math.exp. = n ؛ د = 2 ن

2) توزيع الطلاب
ضع في اعتبارك متغيرين عشوائيين مستقلين: Z ، الذي له توزيع طبيعي وتقييس (أي ، M (Z) = 0 ، σ (Z) = 1) ، و V ، موزعة وفقًا لقانون chi-square مع k درجة من الحرية. ثم القيمة
له توزيع يسمى t - Distribution أو توزيع Student مع k درجة من الحرية. في هذه الحالة ، يسمى k "عدد درجات الحرية" لتوزيع الطالب.
مع زيادة عدد درجات الحرية ، يقترب توزيع الطالب بسرعة من الوضع الطبيعي.
تم تقديم هذا التوزيع في عام 1908 من قبل الإحصائي الإنجليزي دبليو جوسيه ، الذي كان يعمل في مصنع للبيرة. تم استخدام الأساليب الإحصائية-الاحتمالية لاتخاذ القرارات الاقتصادية والتقنية في هذا المصنع ، لذلك منعت إدارته V.Gosset من نشر مقالات علمية باسمه. وبهذه الطريقة ، تمت حماية الأسرار التجارية ، "الدراية" في شكل طرق إحصائية احتمالية طورها دبليو جوسيت. ومع ذلك ، فقد تمكن من النشر تحت الاسم المستعار "الطالب". يُظهر تاريخ Gosset-Student أنه قبل مائة عام ، كانت الكفاءة الاقتصادية الكبيرة لأساليب اتخاذ القرار الاحتمالي والإحصائي واضحة للمديرين البريطانيين.

قبل أواخر التاسع عشرالقرن ، كان التوزيع الطبيعي يعتبر القانون العالمي لتغير البيانات. ومع ذلك ، لاحظ K.Pearson أن الترددات التجريبية يمكن أن تختلف اختلافًا كبيرًا عن التوزيع الطبيعي. كان السؤال كيف يمكن إثبات ذلك. لم يتطلب فقط مقارنة رسومية ، وهو أمر شخصي ، ولكن أيضًا تبريرًا كميًا صارمًا.
وهكذا تم اختراع المعيار χ 2(مربع كاي) ، الذي يختبر أهمية التناقض بين الترددات التجريبية (المرصودة) والنظرية (المتوقعة). حدث هذا مرة أخرى في عام 1900 ، ولكن المعيار لا يزال قيد الاستخدام حتى اليوم. علاوة على ذلك ، فقد تم تكييفها لحل مجموعة واسعة من المهام. بادئ ذي بدء ، هذا هو تحليل البيانات الاسمية ، أي تلك التي يتم التعبير عنها ليس بالكمية ، ولكن بالانتماء إلى فئة. على سبيل المثال ، فئة السيارة وجنس المشارك في التجربة ونوع النبات وما إلى ذلك. لا يمكن استخدام هذه البيانات. عمليات رياضيةمثل الجمع والضرب ، بالنسبة لهم يمكنك فقط حساب الترددات.
نشير إلى الترددات المرصودة أوه (لوحظ)، مُتوقع - E (متوقع). كمثال ، لنأخذ نتيجة رمي النرد 60 مرة. إذا كان متماثلًا وموحدًا ، فإن احتمال ظهور أي جانب هو 1/6 وبالتالي فإن العدد المتوقع من كل جانب قادم هو 10 (1/6 ∙ 60). نكتب الترددات المرصودة والمتوقعة في جدول ونرسم مدرج تكراري.
الفرضية الصفرية هي أن الترددات متسقة ، أي أن البيانات الفعلية لا تتعارض مع المتوقع. الفرضية البديلة هي أن الانحرافات في الترددات تتجاوز التقلبات العشوائية ، أي أن التناقضات ذات دلالة إحصائية. للوصول إلى نتيجة صارمة ، نحن بحاجة.
- مقياس معمم للاختلاف بين الترددات المرصودة والمتوقعة.
- يتم توزيع هذا المقياس تحت صحة الفرضية القائلة بعدم وجود فروق.
لنبدأ بالمسافة بين الترددات. إذا أخذنا الفرق فقط يا - إي، إذن سيعتمد هذا الإجراء على حجم البيانات (الترددات). على سبيل المثال ، 20-5 = 15 و 1020 - 1005 = 15. في كلتا الحالتين ، يكون الفرق 15. لكن في الحالة الأولى ، تكون الترددات المتوقعة أقل بثلاث مرات من الترددات المرصودة ، وفي الحالة الثانية ، 1.5 فقط ٪. نحتاج إلى مقياس نسبي لا يعتمد على المقياس.
دعنا ننتبه إلى الحقائق التالية. بشكل عام ، يمكن أن يكون عدد التدرجات التي يتم فيها قياس الترددات أكبر بكثير ، وبالتالي فإن احتمال أن تقع ملاحظة واحدة في فئة أو أخرى يكون ضئيلًا نوعًا ما. إذا كان الأمر كذلك ، فإن توزيع مثل هذا المتغير العشوائي سوف يخضع لقانون الأحداث النادرة ، المعروف باسم قانون بواسون. في قانون بواسون ، كما هو معروف ، قيمة التوقع الرياضي والتباين هما نفس الشيء (المعلمة λ ). ومن ثم ، التردد المتوقع لبعض فئات المتغير الاسمي إيسيكون في وقت واحد وتشتت لها. علاوة على ذلك ، يميل قانون بواسون مع عدد كبير من الملاحظات إلى الوضع الطبيعي. بدمج هاتين الحقيقتين ، نحصل على أنه إذا كانت الفرضية حول الاتفاق بين الترددات المرصودة والمتوقعة صحيحة ، مع عدد كبير من الملاحظات، تعبير
سوف نحصل على .
من المهم أن نتذكر أن الحالة الطبيعية ستظهر فقط عند الترددات العالية بما فيه الكفاية. من المقبول عمومًا في الإحصائيات أن العدد الإجمالي للملاحظات (مجموع الترددات) يجب أن يكون 50 على الأقل وأن يكون التردد المتوقع في كل تدرج على الأقل 5. في هذه الحالة فقط ، سيكون للقيمة الموضحة أعلاه معيار عادي توزيع. لنفترض أنه تم استيفاء هذا الشرط.
يحتوي التوزيع الطبيعي القياسي على جميع القيم تقريبًا ضمن ± 3 (قاعدة سيغما الثلاثة). وبالتالي ، فقد تلقينا فرقًا نسبيًا في الترددات لتدرج واحد. نحن بحاجة إلى مقياس معمم. لا يمكنك فقط جمع كل الانحرافات - نحصل على 0 (احزر السبب). اقترح بيرسون إضافة مربعات هذه الانحرافات.
![]()
هذه هي العلامات معيار χ 2بيرسون. إذا كانت الترددات تتوافق حقًا مع الترددات المتوقعة ، فستكون قيمة المعيار صغيرة نسبيًا (لأن معظم الانحرافات قريبة من الصفر). ولكن إذا تبين أن المعيار كبير ، فإن هذا يشهد لصالح وجود اختلافات كبيرة بين الترددات.
يصبح المعيار "كبيرًا" عندما يصبح حدوث مثل هذه القيمة أو حتى أكبر منها أمرًا غير محتمل. ولحساب مثل هذا الاحتمال ، من الضروري معرفة توزيع المعيار عند تكرار التجربة عدة مرات ، عندما تكون فرضية اتفاق التردد صحيحة.
كما ترى ، تعتمد قيمة مربع كاي أيضًا على عدد المصطلحات. وكلما زاد عددهم ، زادت قيمة المعيار ، لأن كل مصطلح سيساهم في المجموع. لذلك ، لكل كمية مستقلحيث سيكون لها توزيعها الخاص. لقد أتضح أن χ 2هي مجموعة كاملة من التوزيعات.
وها نحن نصل إلى لحظة حساسة. ما هو الرقم مستقلشروط؟ يبدو أن أي مصطلح (أي انحراف) مستقل. اعتقد ك. بيرسون ذلك أيضًا ، لكن تبين أنه كان مخطئًا. في الواقع ، سيكون عدد المصطلحات المستقلة أقل بمقدار واحد من عدد تدرجات المتغير الاسمي ن. لماذا؟ لأنه إذا كان لدينا عينة تم حساب مجموع الترددات الخاصة بها بالفعل ، فيمكن دائمًا تعريف أحد الترددات على أنه الفرق بين العدد الإجمالي ومجموع كل الترددات الأخرى. وبالتالي ، سيكون الاختلاف أقل إلى حد ما. هذه الحقيقةلاحظ رونالد فيشر 20 عامًا بعد أن طور بيرسون معياره. حتى الطاولات كان لا بد من إعادة بنائها.
في هذه المناسبة ، قدم فيشر مفهومًا جديدًا للإحصاءات - درجة من الحرية(درجات الحرية) ، وهو عدد المصطلحات المستقلة في المجموع. مفهوم درجات الحرية له تفسير رياضي ولا يظهر إلا في التوزيعات المرتبطة بالعادي (Student و Fisher-Snedekor و chi-square نفسه).
لفهم معنى درجات الحرية بشكل أفضل ، دعنا ننتقل إلى النظير المادي. تخيل نقطة تتحرك بحرية في الفضاء. لديها 3 درجات من الحرية ، لأن يمكن أن تتحرك في أي اتجاه من الفضاء ثلاثي الأبعاد. إذا تحركت نقطة على طول أي سطح ، فهذا يعني أنها تتمتع بالفعل بدرجتين من الحرية (للأمام - للخلف ، ولليمين - لليسار) ، على الرغم من استمرار وجودها في الفضاء ثلاثي الأبعاد. النقطة التي تتحرك على طول الربيع هي مرة أخرى في الفضاء ثلاثي الأبعاد ، ولكن لديها درجة واحدة فقط من الحرية ، لأن يمكن أن تتحرك إما للأمام أو للخلف. كما ترى ، فإن المساحة التي يوجد بها الكائن لا تتوافق دائمًا مع حرية الحركة الحقيقية.
قد يعتمد أيضًا توزيع معيار إحصائي تقريبًا على عدد أقل من العناصر من الشروط اللازمة لحسابه. في الحالة العامة ، يكون عدد درجات الحرية أقل من عدد الملاحظات بعدد التبعيات المتاحة. إنها رياضيات بحتة ، لا سحر.
إذن التوزيع χ 2هي عائلة من التوزيعات ، كل منها يعتمد على معيار درجات الحرية. والتعريف الرسمي لاختبار كاي سكوير هو كما يلي. توزيع χ 2(مربع تشي) مع كدرجات الحرية هي توزيع مجموع المربعات كالمتغيرات العشوائية العادية المستقلة.
بعد ذلك ، يمكننا الانتقال إلى الصيغة نفسها ، والتي وفقًا لها يتم حساب دالة توزيع كاي تربيع ، ولكن ، لحسن الحظ ، تم حساب كل شيء بالنسبة لنا منذ فترة طويلة. للحصول على احتمال الاهتمام ، يمكنك استخدام إما الجدول الإحصائي المقابل أو وظيفة جاهزة في برنامج متخصص ، والذي يتوفر حتى في Excel.
من المثير للاهتمام أن نرى كيف يتغير شكل توزيع مربع كاي اعتمادًا على عدد درجات الحرية.

مع زيادة درجات الحرية ، يميل توزيع مربع كاي إلى أن يكون طبيعيًا. هذا ما يفسره عمل نظرية الحد المركزي ، والتي بموجبها يكون المجموع عدد كبيرالمتغيرات العشوائية المستقلة لها توزيع طبيعي. لا يقول أي شيء عن المربعات.
اختبار فرضية مربع تشي
لذلك نأتي إلى اختبار الفرضيات باستخدام طريقة مربع كاي. بشكل عام ، تظل التقنية قائمة. تم طرح فرضية فارغة مفادها أن الترددات المرصودة تتوافق مع الترددات المتوقعة (أي لا يوجد فرق بينها ، حيث إنها مأخوذة من نفس السكان). إذا كانت هذه هي الحالة ، فسيكون الانتشار صغيرًا نسبيًا ، ضمن حدود التقلبات العشوائية. يتم تحديد مقياس الانتشار عن طريق اختبار مربع كاي. بعد ذلك ، إما أن يتم مقارنة المعيار نفسه بالقيمة الحرجة (لمستوى الأهمية المقابل ودرجات الحرية) ، أو بشكل صحيح ، يتم حساب المستوى p المرصود ، أي احتمال الحصول على هذه القيمة أو حتى قيمة أكبر للمعيار تحت صلاحية الفرضية الصفرية.

لأن نظرًا لأننا مهتمون باتفاق الترددات ، فسيتم رفض الفرضية عندما يكون المعيار أكبر من المستوى الحرج. أولئك. المعيار أحادي الجانب. ومع ذلك ، في بعض الأحيان (في بعض الأحيان) يكون مطلوبًا اختبار فرضية اليد اليسرى. على سبيل المثال ، عندما تكون البيانات التجريبية مشابهة جدًا لتلك النظرية. ثم يمكن أن يقع المعيار في منطقة غير محتملة ، ولكن بالفعل على اليسار. النقطة المهمة هي أن في فيفو، فمن غير المرجح الحصول على ترددات تتطابق عمليًا مع الترددات النظرية. هناك دائما بعض العشوائية التي تعطي خطأ. ولكن إذا لم يكن هناك مثل هذا الخطأ ، فربما تكون البيانات مزورة. لكن مع ذلك ، عادة ما يتم اختبار الفرضية اليمنى.
دعنا نعود إلى مشكلة النرد. احسب قيمة اختبار مربع كاي وفقًا للبيانات المتاحة.
لنجد الآن القيمة المجدولة للمعيار عند 5 درجات من الحرية ( ك) ومستوى دلالة 0.05 ( α ).

إنه χ2 0.05 ؛ 5 = 11,1.
دعنا نقارن القيمة الفعلية والجداول. 3.4 ( χ 2) < 11,1 (χ2 0.05 ؛ 5). تبين أن المعيار المحسوب أصغر ، مما يعني أن فرضية المساواة (الموافقة) للترددات لم يتم رفضها. في الشكل ، يبدو الوضع هكذا.

إذا سقطت القيمة المحسوبة في المنطقة الحرجة ، فسيتم رفض الفرضية الصفرية.
سيكون من الأصح حساب المستوى p أيضًا. للقيام بذلك ، تحتاج إلى إيجاد أقرب قيمة في الجدول لعدد معين من درجات الحرية والاطلاع على مستوى الأهمية المقابل. لكن هذا القرن الماضي. نحن نستخدم جهاز كمبيوتر ، وخاصة MS Excel. يحتوي Excel على العديد من الوظائف المتعلقة بـ chi-square.

فيما يلي وصف موجز لها.
XI2.OBR- القيمة الحرجة للمعيار لاحتمال معين على اليسار (كما في الجداول الإحصائية)
chi2.ex.phهي القيمة الحرجة للمعيار لاحتمال معين على اليمين. الوظيفة تكرر بشكل أساسي الوظيفة السابقة. ولكن هنا يمكنك تحديد المستوى على الفور α ، بدلاً من طرحها من 1. هذا أكثر ملاءمة ، لأن في معظم الحالات ، يكون المطلوب هو الذيل الصحيح للتوزيع.
CH2.DIST- مستوى p على اليسار (يمكن حساب الكثافة).
HI2.DIST.PH- مستوى p على اليمين.
HI2.TEST- يقوم بإجراء اختبار مربع كاي على نطاقي تردد معينين في وقت واحد. يتم أخذ عدد درجات الحرية أقل بمقدار واحد من عدد الترددات في العمود (كما ينبغي أن يكون) ، مع إرجاع قيمة المستوى p.
في الوقت الحالي ، لنحسب في تجربتنا القيمة الحرجة (الجدولية) لـ 5 درجات من الحرية و 0.05 ألفا. صيغة Excelسيبدو هكذا:
CH2.OBR (0.95 ؛ 5)
chi2.inv.rx (0.05؛ 5)
ستكون النتيجة هي نفسها - 11.0705. هذه هي القيمة التي نراها في الجدول (مقربة إلى منزلة عشرية واحدة).
أخيرًا ، نحسب المستوى p لـ 5 درجات من الحرية للمعيار χ 2= 3.4. نحتاج إلى الاحتمال على اليمين ، لذلك نأخذ الوظيفة مع إضافة RH (الذيل الأيمن)
CH2.DIST.RH (3.4 ؛ 5) = 0.63857
لذلك ، مع 5 درجات من الحرية ، احتمال الحصول على قيمة المعيار χ 2= 3.4 فأكثر تساوي 64٪ تقريبًا. بطبيعة الحال ، لا يتم رفض الفرضية (المستوى p أكبر من 5٪) ، والترددات في توافق جيد جدًا.
والآن دعنا نتحقق من الفرضية المتعلقة باتفاق التردد باستخدام دالة CH2.TEST.

لا توجد جداول ، ولا حسابات مرهقة. عند تحديد الأعمدة ذات الترددات المرصودة والمتوقعة كوسيطات للوظيفة ، نحصل على المستوى p على الفور. جمال.
تخيل الآن أنك تلعب النرد بنوع مريب. يظل توزيع النقاط من 1 إلى 5 كما هو ، لكنه يتدحرج 26 ستًا (يصبح عدد جميع القوائم 78).

تبين أن المستوى P في هذه الحالة هو 0.003 ، وهو أقل بكثير من 0.05. هناك أسباب جدية للشك في صحة النرد. هذا ما يبدو عليه هذا الاحتمال في مخطط توزيع مربع كاي.

تبين أن معيار chi-square نفسه هنا هو 17.8 ، وهو بطبيعة الحال أكثر من المعيار الجدولي (11.1).
آمل أن أكون قادرًا على شرح ما هو معيار جودة الملاءمة. χ 2(مربع كاي) بيرسون وكيف يتم اختبار الفرضيات الإحصائية معها.
أخيرًا ، مرة أخرى حالة مهمة! يعمل اختبار مربع كاي بشكل صحيح فقط عندما يتجاوز عدد جميع الترددات 50 ، ولا تقل القيمة الدنيا المتوقعة لكل تدرج عن 5. إذا كان التردد المتوقع في أي فئة أقل من 5 ، ولكن مجموع كل الترددات يتجاوز 50 ، يتم دمج هذه الفئة مع أقرب فئة بحيث يتجاوز إجمالي ترددها 5. إذا لم يكن ذلك ممكنًا ، أو كان مجموع الترددات أقل من 50 ، فعندئذٍ أكثر طرق دقيقةاختبار الفرضيات. سنتحدث عنها مرة أخرى.
يوجد أدناه مقطع فيديو حول كيفية اختبار فرضية باستخدام اختبار مربع كاي في Excel.
وزارة التربية والتعليم والعلوم في الاتحاد الروسي
الوكالة الفيدرالية للتعليم لمدينة إيركوتسك
بايكال جامعة الدولةالاقتصاد والقانون
قسم المعلوماتية وعلم التحكم الآلي
توزيع مربع كاي وتطبيقه
Kolmykova آنا أندريفنا
طالبة في السنة الثانية
المجموعة IS-09-1
إيركوتسك 2010
مقدمة
1. توزيع مربع كاي
طلب
خاتمة
فهرس
مقدمة
كيف يتم استخدام مناهج وأفكار ونتائج نظرية الاحتمالات في حياتنا؟
القاعدة هي نموذج احتمالي لظاهرة أو عملية حقيقية ، أي نموذج رياضي يتم فيه التعبير عن العلاقات الموضوعية من حيث نظرية الاحتمالات. تستخدم الاحتمالات في المقام الأول لوصف أوجه عدم اليقين التي يجب أن تؤخذ في الاعتبار عند اتخاذ القرارات. يشير هذا إلى كل من الفرص غير المرغوب فيها (المخاطر) والفرص الجذابة ("فرصة الحظ"). في بعض الأحيان يتم إدخال العشوائية عمدًا في الموقف ، على سبيل المثال ، عند سحب القرعة أو الاختيار العشوائي لوحدات التحكم أو إجراء اليانصيب أو استطلاعات المستهلك.
تسمح نظرية الاحتمالات للفرد بحساب الاحتمالات الأخرى التي تهم الباحث.
النموذج الاحتمالي لظاهرة أو عملية هو أساس الإحصاء الرياضي. يتم استخدام سلسلتين متوازيتين من المفاهيم - تلك المتعلقة بالنظرية (نموذج احتمالي) وتلك المتعلقة بالممارسة (عينة من نتائج الملاحظة). على سبيل المثال ، يتوافق الاحتمال النظري مع التردد الموجود من العينة. يتوافق التوقع الرياضي (المتسلسلة النظرية) مع المتوسط الحسابي للعينة (السلاسل العملية). كقاعدة عامة ، فإن خصائص العينة هي تقديرات لتلك النظرية. في نفس الوقت ، الكميات المتعلقة بالسلسلة النظرية "في أذهان الباحثين" ، تشير إلى عالم الأفكار (حسب الفيلسوف اليوناني القديم أفلاطون) ، وهي غير متاحة للقياس المباشر. الباحثون لديهم بيانات انتقائية فقط ، والتي من خلالها يحاولون تحديد خصائص نموذج احتمالي نظري تهمهم.
لماذا نحتاج إلى نموذج احتمالي؟ والحقيقة هي أنه من خلال مساعدتها فقط ، يمكن نقل الخصائص التي تحددها نتائج تحليل عينة معينة إلى عينات أخرى ، وكذلك إلى جميع ما يسمى عموم السكان. يستخدم مصطلح "السكان" للإشارة إلى عدد كبير ولكن محدود من الوحدات قيد الدراسة. على سبيل المثال ، حول إجمالي جميع سكان روسيا أو إجمالي جميع مستهلكي القهوة سريعة التحضير في موسكو. الغرض من المسوحات التسويقية أو الاجتماعية هو نقل البيانات الواردة من عينة من مئات أو آلاف الأشخاص إلى عموم السكان من عدة ملايين من الناس. في مراقبة الجودة ، تعمل مجموعة من المنتجات كعامة السكان.
لنقل الاستنتاجات من عينة إلى عدد أكبر من السكان ، هناك حاجة إلى بعض الافتراضات حول العلاقة بين خصائص العينة وخصائص هذا المجتمع الأكبر. تستند هذه الافتراضات على نموذج احتمالي مناسب.
بالطبع ، من الممكن معالجة بيانات العينة دون استخدام نموذج احتمالي واحد أو آخر. على سبيل المثال ، يمكنك حساب المتوسط الحسابي للعينة ، وحساب تكرار استيفاء شروط معينة ، وما إلى ذلك. ومع ذلك ، فإن نتائج الحسابات سوف تنطبق فقط على عينة محددة ؛ نقل الاستنتاجات التي تم الحصول عليها بمساعدتهم إلى أي مجموعة أخرى غير صحيح. يشار إلى هذا النشاط أحيانًا باسم "تحليل البيانات". بالمقارنة مع الأساليب الإحصائية الاحتمالية ، فإن تحليل البيانات له قيمة معرفية محدودة.
لذلك ، فإن استخدام النماذج الاحتمالية القائمة على تقدير واختبار الفرضيات بمساعدة خصائص العينة هو جوهر طرق اتخاذ القرار الإحصائي الاحتمالي.
توزيع مربع كاي
يحدد التوزيع الطبيعي ثلاث توزيعات تستخدم الآن غالبًا في معالجة البيانات الإحصائية. هذه هي توزيعات بيرسون ("تشي - سكوير") ، ستيودنت وفيشر.
سنركز على التوزيع
("تشي - مربع"). تمت دراسة هذا التوزيع لأول مرة من قبل عالم الفلك F.Helmert في عام 1876. فيما يتعلق بنظرية جاوس للأخطاء ، درس مجاميع المربعات من ن معيار مستقل متغيرات عشوائية موزعة بشكل طبيعي. أطلق كارل بيرسون لاحقًا على وظيفة التوزيع هذه "مربع تشي". والآن أصبح التوزيع يحمل اسمه.نظرًا لارتباطه الوثيق بالتوزيع الطبيعي ، يلعب توزيع χ2 دورًا مهمًا في نظرية الاحتمالات والإحصاءات الرياضية. يصف توزيع χ2 والعديد من التوزيعات الأخرى التي تم تحديدها بواسطة توزيع χ2 (مثل توزيع الطلاب) توزيعات العينات للوظائف المختلفة من الملاحظات الموزعة بشكل طبيعي ويتم استخدامها لإنشاء فترات الثقة والاختبارات الإحصائية.
توزيع بيرسون
(كاي - تربيع) - توزيع متغير عشوائي ، حيث X1 ، X2 ، ... ، Xn - المتغيرات العشوائية المستقلة العادية ، والتوقع الرياضي لكل منها يساوي صفرًا ، والانحراف المعياري واحد.مجموع المربعات
يحددها القانون
("تشي - مربع").في هذه الحالة ، عدد المصطلحات ، أي n ، يسمى "عدد درجات الحرية" لتوزيع مربع كاي.مع زيادة عدد درجات الحرية ، يقترب التوزيع ببطء من الوضع الطبيعي.
كثافة هذا التوزيع

لذلك ، يعتمد التوزيع χ2 على معلمة واحدة n - عدد درجات الحرية.
دالة التوزيع χ2 لها الشكل:

إذا كان χ2≥0. (2.7.)
يوضح الشكل 1 رسمًا بيانيًا لكثافة الاحتمال ودالة التوزيع χ2 لدرجات مختلفة من الحرية.

الصورة 1اعتماد كثافة الاحتمال φ (x) في التوزيع χ2 (مربع كاي) لعدد مختلف من درجات الحرية.
لحظات توزيع "تشي سكوير":
يتم استخدام توزيع مربع كاي في تقدير التباين (باستخدام فاصل الثقة) ، وفي اختبار فرضيات التوافق ، والتجانس ، والاستقلالية ، وبشكل أساسي للمتغيرات النوعية (المصنفة) التي تأخذ عددًا محدودًا من القيم ، وفي العديد من المهام الأخرى للبيانات الإحصائية تحليل.
2. "Chi-square" في مشاكل تحليل البيانات الإحصائية
تستخدم الأساليب الإحصائية لتحليل البيانات في جميع مجالات النشاط البشري تقريبًا. يتم استخدامها كلما كان ذلك ضروريًا للحصول على أي أحكام حول مجموعة (كائنات أو مواضيع) وإثباتها مع بعض التباين الداخلي.
يمكن حساب المرحلة الحديثة من تطوير الأساليب الإحصائية منذ عام 1900 ، عندما أسس الإنجليزي ك. بيرسون مجلة "Biometrika". الثلث الأول من القرن العشرين مرت تحت علامة الإحصاء البارامترية. تمت دراسة الطرق المعتمدة على تحليل البيانات من العائلات البارامترية للتوزيعات التي وصفتها منحنيات عائلة بيرسون. كان التوزيع الطبيعي هو الأكثر شيوعًا. تم استخدام معايير Pearson و Student و Fisher لاختبار الفرضيات. تم اقتراح طريقة الاحتمالية القصوى وتحليل التباين وصياغة الأفكار الرئيسية لتخطيط التجربة.
يعد توزيع مربع كاي أحد أكثر التوزيعات استخدامًا في الإحصائيات لاختبار الفرضيات الإحصائية. على أساس توزيع "مربع كاي" ، تم إنشاء أحد أقوى اختبارات جودة التوافق ، وهو اختبار بيرسون "مربع كاي".
اختبار جودة الملاءمة هو معيار لاختبار الفرضية حول القانون المقترح للتوزيع المجهول.
يستخدم اختبار χ2 ("مربع كاي") لاختبار فرضية التوزيعات المختلفة. هذا هو جدارة.
صيغة حساب المعيار تساوي

حيث m و m 'هما الترددان التجريبي والنظري على التوالي
التوزيع قيد النظر ؛
ن هو عدد درجات الحرية.
للتحقق ، نحتاج إلى مقارنة الترددات التجريبية (المرصودة) والنظرية (المحسوبة على افتراض التوزيع الطبيعي).
إذا كانت الترددات التجريبية تتطابق تمامًا مع الترددات المحسوبة أو المتوقعة ، فإن S (E - T) = 0 والمعيار χ2 سيكون أيضًا مساويًا للصفر. إذا لم تكن S (E - T) مساوية للصفر ، فسيشير ذلك إلى وجود تناقض بين الترددات المحسوبة والترددات التجريبية للسلسلة. في مثل هذه الحالات ، من الضروري تقييم أهمية المعيار 2 ، والذي يمكن أن يختلف نظريًا من صفر إلى ما لا نهاية. يتم ذلك عن طريق مقارنة القيمة التي تم الحصول عليها بالفعل من 2ph مع قيمتها الحرجة (χ2st). يتم دحض الفرضية الصفرية ، أي افتراض أن التناقض بين الترددات التجريبية والنظرية أو المتوقعة عشوائي ، إذا كانت 2ph أكبر من أو تساوي إلى 2st لمستوى الأهمية المقبول (أ) وعدد درجات الحرية (ن).
في التمرين البحث البيولوجيغالبًا ما يكون من الضروري اختبار فرضية واحدة أو أخرى ، أي معرفة إلى أي مدى تؤكد المادة الواقعية التي حصل عليها المجرب الافتراض النظري ، وإلى أي مدى تتوافق البيانات التي تم تحليلها مع تلك المتوقعة نظريًا. تنشأ مشكلة التقييم الإحصائي للفرق بين البيانات الفعلية والتوقع النظري ، وتحديد الحالات وبدرجة الاحتمالية التي يمكن اعتبار هذا الاختلاف موثوقًا بها ، وعلى العكس من ذلك ، متى يجب اعتباره غير مهم وغير مهم ضمن حدود فرصة. في الحالة الأخيرة ، يتم الاحتفاظ بالفرضية ، والتي يتم على أساسها حساب البيانات أو المؤشرات المتوقعة نظريًا. طريقة تشي مربع (χ 2). غالبًا ما يشار إلى هذا المقياس باسم "اختبار الملاءمة" أو "اختبار الملاءمة" من بيرسون. بمساعدتها ، يمكن للمرء أن يحكم ، مع احتمالية متفاوتة ، على درجة التطابق بين البيانات التي تم الحصول عليها تجريبياً والبيانات المتوقعة نظرياً.
من وجهة نظر رسمية ، تتم مقارنة سلسلتين متغايرتين ومجموعتين: أحدهما توزيع تجريبي والآخر عينة بنفس المعلمات ( ن, م, سوآخرون) كإجراء تجريبي ، لكن توزيع التردد الخاص به مبني في توافق صارم مع القانون النظري المختار (عادي ، بواسون ، ذو الحدين ، إلخ) ، الذي يفترض أن سلوك المتغير العشوائي قيد الدراسة يطيع.
في نظرة عامةيمكن كتابة صيغة معيار المطابقة على النحو التالي:
أين أ -تردد المراقبة الفعلي ،
أ-التردد المتوقع نظريًا لفئة معينة.
تفترض الفرضية الصفرية عدم وجود فروق ذات دلالة إحصائية بين التوزيعات المقارنة. لتقييم أهمية هذه الاختلافات ، ينبغي للمرء أن يشير إلى جدول خاص لقيم مربع كاي الحرجة (الجدول 9 ص) ومقارنة القيمة المحسوبة χ 2 باستخدام جدول ، قرر ما إذا كان التوزيع التجريبي ينحرف بشكل كبير عن التوزيع النظري أم لا. وبالتالي ، فإن فرضية عدم وجود هذه الاختلافات إما سيتم دحضها أو دعمها. إذا كانت القيمة المحسوبة χ 2 يساوي أو يتجاوز الجدول χ ² ( α , مدافع) ، قرر أن التوزيع التجريبي يختلف اختلافًا كبيرًا عن التوزيع النظري. وبالتالي ، فإن فرضية عدم وجود هذه الاختلافات سيتم دحضها. لو χ ² < χ ² ( α , مدافع) ، تظل الفرضية الصفرية صالحة. من المقبول عمومًا النظر في المستوى المقبول للأهمية α = 0.05 ، لأنه في هذه الحالة هناك فرصة بنسبة 5٪ فقط لصحة الفرضية الصفرية ، وبالتالي ، هناك أسباب كافية (95٪) لرفضها.
مشكلة معينة هي التحديد الصحيح لعدد درجات الحرية ( مدافع) ، والتي من أجلها يتم أخذ قيم المعيار من الجدول. لتحديد عدد درجات الحرية من الرقم الإجماليالطبقات كتحتاج إلى طرح عدد القيود (أي عدد المعلمات المستخدمة لحساب الترددات النظرية).
اعتمادًا على نوع توزيع السمة قيد الدراسة ، ستتغير معادلة حساب عدد درجات الحرية. ل بديلالتوزيعات ( ك= 2) يتم تضمين معلمة واحدة فقط (حجم العينة) في الحسابات ، وبالتالي ، فإن عدد درجات الحرية هو مدافع= ك−1 = 2−1 = 1. ل متعدد الحدودصيغة التوزيع مشابهة: مدافع= ك-1. للتحقق من الامتثال سلسلة الاختلافتوزيع بواسونتم استخدام معلمتين بالفعل - حجم العينة والقيمة المتوسطة (بالتزامن عدديًا مع التباين) ؛ عدد درجات الحرية مدافع= ك−2. عند التحقق من مراسلات التوزيع التجريبي ، فإن المتغير طبيعيأو ذات الحدينالقانون ، يتم أخذ عدد درجات الحرية على أنه عدد الفصول الفعلية مطروحًا منه ثلاثة شروط لبناء سلسلة - حجم العينة والمتوسط والتباين ، مدافع= ك−3. وتجدر الإشارة على الفور إلى أن المعيار χ² يعمل فقط مع العينات حجم لا يقل عن 25 خيار، وترددات الفصول الفردية يجب أن تكون 4 على الأقل.
أولاً ، نوضح تطبيق اختبار مربع كاي باستخدام مثال التحليل تقلبية بديلة. في إحدى تجارب دراسة الوراثة في الطماطم ، تم العثور على 3629 فاكهة حمراء و 1176 فاكهة صفراء. يجب أن تكون النسبة النظرية للترددات عند تقسيم السمات في الجيل الهجين الثاني 3: 1 (75٪ إلى 25٪). هل يتم تنفيذه؟ بمعنى آخر ، هل هذه العينة مأخوذة من نفس الجمهور العام حيث تكون نسبة التردد 3: 1 أو 0.75: 0.25؟
لنقم بتكوين جدول (جدول 4) ، نملأه بقيم الترددات التجريبية ونتائج حساب الترددات النظرية وفقًا للصيغة:
أ = ن ∙ ص ،
أين ص- الترددات النظرية (أسهم متغير من نوع معين) ،
ن-حجم العينة.
على سبيل المثال، أ 2 = ن ∙ ص 2 = 4805∙0.25 = 1201.25 ≈ 1201.
ضع في اعتبارك التطبيق بتنسيقآنسةاكسلاختبار Pearson chi-square لاختبار فرضيات بسيطة.
بعد تلقي البيانات التجريبية (أي عندما يكون هناك بعض عينة) عادة يتم اختيار قانون التوزيع الذي يصف المتغير العشوائي الذي يمثله المعطى على أفضل وجه أخذ العينات. التحقق من مدى جودة وصف البيانات التجريبية بواسطة قانون التوزيع النظري المختار يتم باستخدامه معايير الموافقة. فرضية العدم، عادة ما تكون هناك فرضية مفادها أن توزيع متغير عشوائي يساوي بعض القوانين النظرية.
لنلق نظرة أولاً على التطبيق اختبار Pearson لجودة الملاءمة X 2 (مربع كاي)فيما يتعلق بالفرضيات البسيطة (من المفترض أن تكون معلمات التوزيع النظري معروفة). ثم - ، عندما يتم تحديد نموذج التوزيع فقط ، ومعلمات هذا التوزيع والقيمة إحصائيات X 2 يتم تقديرها / احتسابها على أساس ذلك عينات.
ملحوظة: في أدب اللغة الإنجليزية ، إجراءات التقديم اختبار بيرسون لمدى الملاءمة X 2 له اسم خير مربع تشي لاختبار الملاءمة.
تذكر إجراء اختبار الفرضيات:
- قائم على عيناتيتم احتساب القيمة إحصائيات، والذي يتوافق مع نوع الفرضية التي يتم اختبارها. على سبيل المثال ، لاستخدام ر-إحصائيات(إن لم يكن معروفًا) ؛
- تخضع للحقيقة فرضية العدم، وتوزيع هذا إحصائياتمعروف ويمكن استخدامه لحساب الاحتمالات (على سبيل المثال ، لـ ر- إحصائياتهذا )؛
- محسوبة على أساس عيناتمعنى إحصائياتمقارنة بالقيمة الحرجة للقيمة المعطاة () ؛
- فرضية العدمإذا رفضت القيمة إحصائياتأكبر من الحرجة (أو إذا كان احتمال الحصول على هذه القيمة إحصائيات() أقل مستوى الأهمية، وهو النهج المكافئ).
دعونا ننفق اختبار الفرضياتلتوزيعات مختلفة.
حالة منفصلة
افترض أن شخصين يلعبان النرد. كل لاعب لديه مجموعته الخاصة من النرد. يتناوب اللاعبون على رمي 3 أحجار نرد مرة واحدة. يفوز كل جولة من يدحرج أكثر من ست مرات في المرة الواحدة. يتم تسجيل النتائج. أحد اللاعبين ، بعد 100 جولة ، كان يشك في أن عظام خصمه لم تكن متماثلة ، لأن. غالبًا ما يفوز (غالبًا ما يرمي الستات). قرر تحليل مدى احتمالية حدوث مثل هذا العدد من نتائج الخصم.
ملحوظة: لأن 3 نرد ، ثم يمكنك رمي 0 في وقت واحد ؛ 1 ؛ 2 أو 3 ستات ، أي يمكن أن يأخذ المتغير العشوائي 4 قيم.
من نظرية الاحتمال ، نعلم أنه إذا كانت المكعبات متناظرة ، فإن احتمال سقوط الستات يطيع. لذلك ، بعد 100 جولة ، يمكن حساب ترددات الست باستخدام الصيغة
= BINOM.DIST (A7،3،1 / 6، FALSE) * 100
تفترض الصيغة أن الخلية أ 7 يحتوي على العدد المقابل من الستات التي تم إسقاطها في جولة واحدة.
ملحوظة: الحسابات معطاة بصيغة مثال على ملف على ورقة منفصلة.
للمقارنة لاحظ(لوحظ) و الترددات النظرية(متوقع) سهل الاستخدام.

مع انحراف كبير للترددات المرصودة عن التوزيع النظري ، فرضية العدمحول توزيع متغير عشوائي وفقًا لقانون نظري ، يجب رفضه. بمعنى أنه إذا لم يكن نرد الخصم متماثلًا ، فستكون الترددات الملحوظة "مختلفة بشكل كبير" عن توزيع ثنائي.
في حالتنا ، للوهلة الأولى ، تكون الترددات قريبة جدًا ومن الصعب استخلاص نتيجة لا لبس فيها بدون حسابات. ملائم اختبار Pearson لجودة الملاءمة X 2، بحيث بدلاً من العبارة الذاتية "مختلفة بشكل كبير" ، والتي يمكن إجراؤها على أساس المقارنة الرسوم البيانية، استخدم بيانًا صحيحًا رياضيًا.
دعونا نستخدم حقيقة ذلك قانون أعداد كبيرة التردد المرصود (المرصود) مع زيادة الحجم عيناتيميل n إلى الاحتمال المقابل للقانون النظري (في حالتنا ، قانون ذو الحدين). في حالتنا ، حجم العينة n هو 100.
دعنا نقدم امتحان إحصائيات، والتي نشير إليها بواسطة X 2:

حيث O l هو التردد الملحوظ للأحداث التي أخذها المتغير العشوائي بعض القيم المقبولة ، E l هو التردد النظري المقابل (المتوقع). L هو عدد القيم التي يمكن أن يأخذها متغير عشوائي (في حالتنا يساوي 4).
كما يتضح من الصيغة ، هذا إحصائياتهو مقياس لتقارب الترددات الملحوظة من الترددات النظرية ، أي يمكن استخدامه لتقدير "المسافات" بين هذه الترددات. إذا كان مجموع هذه "المسافات" "كبير جدًا" ، فإن هذه الترددات تكون "مختلفة تمامًا". من الواضح أنه إذا كان المكعب الخاص بنا متماثلًا (أي قابل للتطبيق قانون ذو الحدين) ، فسيكون احتمال أن يكون مجموع "المسافات" "كبيرًا جدًا" صغيرًا. لحساب هذا الاحتمال ، نحتاج إلى معرفة التوزيع إحصائيات X 2 ( إحصائيات X 2 محسوبة على أساس عشوائي عينات، لذلك فهو متغير عشوائي ، وبالتالي ، له متغير خاص به توزيع الاحتمالات).
من التناظرية متعددة الأبعاد نظرية مويفر لابلاس المتكاملةمن المعروف أنه بالنسبة لـ n-> ∞ المتغير العشوائي X 2 يكون مقاربًا مع L - 1 درجة من الحرية.
لذلك إذا كانت القيمة المحسوبة إحصائياتسيكون X 2 (مجموع "المسافات" بين الترددات) أكثر من قيمة حدية معينة ، ومن ثم سيكون لدينا سبب لرفض فرضية العدم. كما في الفحص الفرضيات البارامترية، يتم تعيين قيمة الحد عبر مستوى الأهمية. إذا كان هناك احتمال أن تأخذ الإحصائية X 2 قيمة أقل من أو تساوي القيمة المحسوبة ( ص-معنى) سيكون أقل مستوى الأهمية، الذي - التي فرضية العدميمكن رفضها.
القيمة الإحصائية في حالتنا هي 22.757. احتمالية أن تأخذ إحصائية X 2 قيمة أكبر من أو تساوي 22.757 صغيرة جدًا (0.000045) ويمكن حسابها باستخدام الصيغ
= XI2.DIST.PX (22757 ؛ 4-1)أو
= XI2.TEST (مرصود ؛ متوقع)
ملحوظة: تم تصميم الدالة CH2.TEST () خصيصًا لاختبار العلاقة بين متغيرين فئويين (انظر).
احتمال 0.000045 أقل بكثير من المعتاد مستوى الأهمية 0.05. لذلك ، فإن لدى اللاعب كل الأسباب للشك في أن خصمه قد أساء إلى الأمانة ( فرضية العدمعن صدقه ينكر).

عند تطبيقها المعيار X 2يجب توخي الحذر لضمان أن الحجم عيناتكان n كبيرًا بدرجة كافية ، وإلا فسيكون تقريب التوزيع غير صالح الإحصاء X 2. يُعتبر عادةً أنه يكفي لهذا أن تكون الترددات الملحوظة (المرصودة) أكبر من 5. إذا لم يكن الأمر كذلك ، يتم دمج الترددات المنخفضة في تردد واحد أو ربطها بترددات أخرى ، ويتم تعيين القيمة المجمعة الإجمالي الاحتمال ، وبالتالي ، يتناقص عدد درجات الحرية X 2 - التوزيع.
من أجل تحسين جودة التطبيق المعيار X 2() ، من الضروري تقليل فترات التقسيم (زيادة L ، وبالتالي زيادة العدد درجات الحرية) ، ومع ذلك ، يتم منع هذا من خلال تقييد عدد الملاحظات التي تقع في كل فترة (d.b.> 5).
حالة مستمرة
اختبار بيرسون للصلاحية من الملاءمة X 2 يمكن تطبيقه بنفس الطريقة في حالة.
النظر في بعض أخذ العينات، تتكون من 200 قيمة. فرضية العدمينص علي عينةمصنوع من .
ملحوظة: المتغيرات العشوائية بتنسيق ملف عينة على ورقة مستمرولدت باستخدام الصيغة = NORM.ST.INV (RAND ()). لذلك ، قيم جديدة عيناتيتم إنشاؤها في كل مرة يتم فيها إعادة حساب الورقة.
يمكن تقييم ما إذا كانت مجموعة البيانات المتاحة كافية بصريًا.

كما ترى من الرسم التخطيطي ، تتوافق قيم العينة جيدًا على طول الخط المستقيم. ومع ذلك ، كما هو الحال في اختبار الفرضياتملائم اختبار Pearson لجودة الملاءمة X 2.
للقيام بذلك ، نقسم نطاق تباين المتغير العشوائي إلى فترات زمنية بخطوة 0.5. دعونا نحسب الترددات المرصودة والنظرية. نحسب الترددات المرصودة باستخدام وظيفة FREQUENCY () والوظيفة النظرية - باستخدام دالة NORM.ST.DIST ().
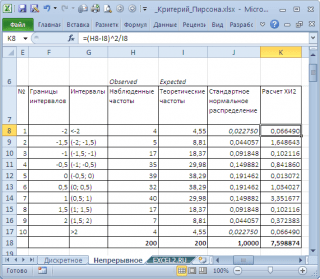
ملحوظة: أما بالنسبة لل حالة منفصلة، فمن الضروري التأكد من ذلك عينةكانت كبيرة جدًا ، ووقعت أكثر من 5 قيم في الفاصل الزمني.
احسب الإحصائيات X 2 وقارنها بالقيمة الحرجة لمحددة معينة مستوى الأهمية(0.05). لأن قمنا بتقسيم نطاق التباين لمتغير عشوائي إلى 10 فترات زمنية ، ثم يكون عدد درجات الحرية 9. يمكن حساب القيمة الحرجة بالصيغة
= XI2.INV.RH (0.05 ؛ 9) أو
= XI2.OBR (1-0.05 ؛ 9)
يظهر الرسم البياني أعلاه أن القيمة الإحصائية هي 8.19 ، وهي أعلى بكثير شديد الأهمية – فرضية العدملم يتم رفضه.
أدناه على أي عينةيفترض قيمة غير محتملة ، وعلى أساس معايير موافقة بيرسون × 2تم رفض الفرضية الصفرية (على الرغم من حقيقة أن القيم العشوائية تم إنشاؤها باستخدام الصيغة = NORM.ST.INV (RAND ())توفير أخذ العيناتمن التوزيع القياسي).

فرضية العدممرفوض ، على الرغم من أن البيانات بصريًا قريبة جدًا من خط مستقيم.
كمثال ، لنأخذ أيضًا أخذ العيناتمن يو (-3 ؛ 3). في هذه الحالة ، حتى من الرسم البياني يتضح ذلك فرضية العدميجب رفضه.

معيار موافقة بيرسون × 2يؤكد ذلك أيضًا فرضية العدميجب رفضه.
المنشورات ذات الصلة
-
.jpg) الحماية الآمنة للنباتات من الأمراض والآفات في شهري يوليو وأغسطس
الحماية الآمنة للنباتات من الأمراض والآفات في شهري يوليو وأغسطس
حتى أسلافنا كانوا يعرفون أن الحصاد الجيد لا يعتمد فقط على العمل الجاد والمسؤول ، ولكن أيضًا على مراحل القمر. اكتشف وأنت مواتية ...
-
 سيؤدي الحصاد القياسي للحبوب إلى انكماش حصاد الحبوب في الاتحاد الروسي
سيؤدي الحصاد القياسي للحبوب إلى انكماش حصاد الحبوب في الاتحاد الروسي
07/18/2017 - 21:03 أخبار بيلاروسيا. بدأ الحصاد الجماعي للحبوب في جنوب غرب البلاد ، وفق ما أورده برنامج أخبار 24 ساعة ...