
Ограничения на критерия. Хи-квадрат тест на Пиърсън. Тестване на прости хипотези с помощта на теста хи-квадрат на Pearson в MS EXCEL

23. Концепция за хи-квадрат и разпределение на Стюдънт и графичен изглед
1) Разпределение (хи-квадрат) с n степени на свобода е разпределението на сумата от квадратите на n независими стандартни нормални случайни променливи.
Разпределение (хи-квадрат)– разпространение случайна променлива(и математическо очакваневсяко от тях е равно на 0, а стандартното отклонение е 1)
къде са случайните променливи ![]() независими и имат еднакво разпределение. В този случай броят на членовете, т.е., се нарича „брой степени на свобода“ на разпределението хи-квадрат. Числото хи-квадрат се определя от един параметър, броя на степените на свобода. С увеличаването на броя на степените на свобода разпределението бавно се доближава до нормалното.
независими и имат еднакво разпределение. В този случай броят на членовете, т.е., се нарича „брой степени на свобода“ на разпределението хи-квадрат. Числото хи-квадрат се определя от един параметър, броя на степените на свобода. С увеличаването на броя на степените на свобода разпределението бавно се доближава до нормалното.
След това сумата от техните квадрати
е случайна променлива, разпределена по така наречения закон хи-квадрат с k = n степени на свобода; ако членовете са свързани с някаква връзка (например ), тогава броят на степените на свобода k = n – 1.
Плътността на това разпределение

тук ![]() - гама функция; по-специално, Г(n + 1) = n! .
- гама функция; по-специално, Г(n + 1) = n! .
Следователно разпределението хи-квадрат се определя от един параметър - броя на степените на свобода k.
Забележка 1. С увеличаването на броя на степените на свобода разпределението хи-квадрат постепенно се доближава до нормалното.
Забележка 2. С помощта на разпределението хи-квадрат се определят много други разпределения, срещани в практиката, например разпределението на случайна променлива - дължината на произволен вектор (X1, X2,..., Xn), координатите на които са независими и се разпределят по нормалния закон.
Разпределението χ2 е разгледано за първи път от R. Helmert (1876) и K. Pearson (1900).
Math.expect.=n; D=2n

2) Разпределение на учениците
Разгледайте две независими случайни променливи: Z, която има нормално разпределение и е нормализирана (т.е. M(Z) = 0, σ(Z) = 1), и V, която е разпределена според закона хи-квадрат с k степени на свобода. След това стойността
има разпределение, наречено t-разпределение или разпределение на Стюдънт с k степени на свобода. В този случай k се нарича „брой степени на свобода“ на разпределението на Стюдънт.
Тъй като броят на степените на свобода се увеличава, разпределението на Student бързо се доближава до нормалното.
Това разпределение е въведено през 1908 г. от английския статистик У. Госет, който работи във фабрика за бира. В тази фабрика са използвани вероятностни и статистически методи за вземане на икономически и технически решения, така че нейното ръководство забранява на В. Госет да публикува научни статии под собственото си име. По този начин бяха защитени търговски тайни и „ноу-хау“ под формата на вероятностни и статистически методи, разработени от V. Gosset. Той обаче имаше възможност да публикува под псевдонима „Студент“. Историята на Gosset-Student показва, че дори преди сто години британските мениджъри са били наясно с по-голямата икономическа ефективност на вероятностно-статистическите методи за вземане на решения.

до края на XIXвек, нормалното разпределение се счита за универсален закон за вариацията на данните. К. Пиърсън обаче отбеляза, че емпиричните честоти могат да се различават значително от нормалното разпределение. Възникна въпросът как да се докаже това. Изисква се не само графично сравнение, което е субективно, но и стриктна количествена обосновка.
Така е измислен критерият χ 2(хи-квадрат), който тества значимостта на разликата между емпирични (наблюдавани) и теоретични (очаквани) честоти. Това се случи още през 1900 г., но критерият се използва и днес. Освен това той е адаптиран за решаване на широк кръг от проблеми. На първо място, това е анализът на номиналните данни, т.е. тези, които се изразяват не чрез количество, а чрез принадлежност към някаква категория. Например класа на автомобила, пола на участника в експеримента, вида на растението и др. Такива данни не могат да бъдат приложени математически операциикато добавяне и умножение, можете само да преброите честотите за тях.
Означаваме наблюдаваните честоти Относно (Наблюдавано), очаквано – E (Очаква се). Като пример, нека вземем резултата от хвърляне на зар 60 пъти. Ако е симетрична и еднаква, вероятността да се получи която и да е страна е 1/6 и следователно очакваният брой да се получи всяка страна е 10 (1/6∙60). Записваме наблюдаваните и очакваните честоти в таблица и чертаем хистограма.
Нулевата хипотеза е, че честотите са последователни, тоест действителните данни не противоречат на очакваните данни. Алтернативна хипотеза е, че отклоненията в честотите надхвърлят случайните флуктуации, т.е. несъответствията са статистически значими. За да направим строго заключение, имаме нужда.
- Обобщена мярка за несъответствието между наблюдаваните и очакваните честоти.
- Разпределението на тази мярка, ако хипотезата, че няма разлики е вярна.
Да започнем с разстоянието между честотите. Ако просто вземете разликата О - Д, тогава такава мярка ще зависи от мащаба на данните (честотите). Например 20 - 5 = 15 и 1020 - 1005 = 15. И в двата случая разликата е 15. Но в първия случай очакваните честоти са 3 пъти по-малки от наблюдаваните, а във втория случай - само 1,5 %. Нуждаем се от относителна мярка, която не зависи от мащаба.
Нека обърнем внимание на следните факти. Като цяло, броят на градациите, в които се измерват честотите, може да бъде много по-голям, така че вероятността едно наблюдение да попадне в една или друга категория е доста малка. Ако е така, тогава разпределението на такава случайна променлива ще се подчинява на закона за редките събития, известен като Закон на Поасон. В закона на Поасон, както е известно, стойността на математическото очакване и дисперсията съвпадат (параметър λ ). Това означава, че очакваната честота за някоя категория на номиналната променлива E iще бъде едновременно и неговата дисперсия. Освен това законът на Поасон клони към нормалното при голям брой наблюдения. Комбинирайки тези два факта, получаваме, че ако хипотезата за съответствието между наблюдаваните и очакваните честоти е вярна, тогава, с голям брой наблюдения, израз
Ще има.
Важно е да запомните, че нормалното ще се появи само при достатъчно високи честоти. В статистиката е общоприето, че общият брой наблюдения (сума от честоти) трябва да бъде най-малко 50 и очакваната честота във всяка градация трябва да бъде най-малко 5. Само в този случай стойността, показана по-горе, ще има стандартна норма разпространение. Да приемем, че това условие е изпълнено.
Стандартното нормално разпределение има почти всички стойности в рамките на ±3 (правилото на трите сигми). Така получихме относителната разлика в честотите за една градация. Имаме нужда от обобщаваща мярка. Не можете просто да съберете всички отклонения - получаваме 0 (познайте защо). Пиърсън предложи да се съберат квадратите на тези отклонения.
![]()
Това е знакът критерий χ 2Пиърсън. Ако честотите наистина отговарят на очакваните, тогава стойността на критерия ще бъде относително малка (тъй като повечето отклонения са около нулата). Но ако критерият се окаже голям, тогава това показва значителни разлики между честотите.
Критерият става „голям“, когато настъпването на такава или дори по-голяма стойност стане малко вероятно. И за да се изчисли такава вероятност, е необходимо да се знае разпределението на критерия, когато експериментът се повтаря многократно, когато хипотезата за съответствие на честотата е вярна.
Както е лесно да се види, стойността на хи-квадрат също зависи от броя на членовете. Колкото повече са, толкова по-голяма стойност трябва да има критерият, тъй като всеки член ще допринесе за общата сума. Следователно за всяко количество независимаусловия, ще има собствено разпространение. Оказва се, че χ 2е цяло семейство от дистрибуции.
И тук стигаме до един деликатен момент. Какво е число независимаусловия? Изглежда, че всеки термин (т.е. отклонение) е независим. Така смяташе и К. Пиърсън, но се оказа, че греши. Всъщност броят на независимите членове ще бъде с един по-малък от броя на градациите на номиналната променлива п. защо Защото, ако имаме извадка, за която сумата от честотите вече е изчислена, тогава една от честотите винаги може да бъде определена като разликата между общия брой и сумата от всички останали. Следователно вариацията ще бъде малко по-малка. Този фактРоналд Фишър забеляза около 20 години след като Пиърсън разработи своя критерий. Дори масите трябваше да бъдат преправени.
По този повод Фишър въвежда нова концепция в статистиката - степен на свобода(степени на свобода), което представлява броя на независимите членове в сумата. Концепцията за степените на свобода има математическо обяснение и се появява само в разпределения, свързани с нормалното (на Стюдънт, на Фишер-Снедекор и самото хи-квадрат).
За да разберем по-добре значението на степените на свобода, нека се обърнем към един физически аналог. Нека си представим точка, която се движи свободно в пространството. Има 3 степени на свобода, т.к може да се движи във всяка посока в триизмерното пространство. Ако една точка се движи по която и да е повърхност, тогава тя вече има две степени на свобода (напред и назад, наляво и надясно), въпреки че продължава да бъде в триизмерното пространство. Точка, движеща се по пружина, отново е в триизмерно пространство, но има само една степен на свобода, т.к може да се движи напред или назад. Както можете да видите, пространството, където се намира обектът, не винаги отговаря на реалната свобода на движение.
Приблизително по същия начин разпределението на статистически критерий може да зависи от по-малък брой елементи от условията, необходими за изчисляването му. Като цяло броят на степените на свобода е по-малък от броя на наблюденията с броя на съществуващите зависимости. Това е чиста математика, без магия.
Така че разпределението χ 2е семейство от разпределения, всяко от които зависи от параметъра степени на свобода. А формалната дефиниция на теста хи-квадрат е следната. Разпределение χ 2(хи-квадрат) s кстепени на свобода е разпределението на сумата от квадрати кнезависими стандартни нормални случайни променливи.
След това можем да преминем към самата формула, която изчислява функцията на разпределение хи-квадрат, но за щастие всичко отдавна е изчислено за нас. За да получите вероятността от интерес, можете да използвате или съответната статистическа таблица, или готова функция в специализиран софтуер, който дори е наличен в Excel.
Интересно е да се види как формата на разпределението хи-квадрат се променя в зависимост от броя на степените на свобода.

С увеличаване на степените на свобода разпределението хи-квадрат има тенденция да бъде нормално. Това се обяснява с действието на централната пределна теорема, според която сумата голямо количествонезависимите случайни променливи имат нормално разпределение. Не пише нищо за квадрати)).
Проверка на хипотези с помощта на теста хи-квадрат
Сега стигаме до тестване на хипотези с помощта на метода хи-квадрат. Като цяло технологията остава. Нулевата хипотеза е, че наблюдаваните честоти съответстват на очакваните (т.е. няма разлика между тях, защото са взети от една и съща популация). Ако това е така, тогава разсейването ще бъде относително малко, в рамките на случайните колебания. Мярката за дисперсия се определя с помощта на теста хи-квадрат. След това или самият критерий се сравнява с критичната стойност (за съответното ниво на значимост и степени на свобода), или, което е по-правилно, се изчислява наблюдаваното p-ниво, т.е. вероятността да се получи същата или дори по-голяма стойност на критерия, ако нулевата хипотеза е вярна.

защото ние се интересуваме от съответствието на честотите, тогава хипотезата ще бъде отхвърлена, когато критерият е по-голям от критичното ниво. Тези. критерият е едностранен. Въпреки това, понякога (понякога) е необходимо да се тества лявата хипотеза. Например, когато емпиричните данни са много сходни с теоретичните данни. Тогава критерият може да попадне в малко вероятна област, но отляво. Въпросът е, че в природни условия, едва ли ще се получат честоти, които практически съвпадат с теоретичните. Винаги има някаква случайност, която дава грешка. Но ако няма такава грешка, тогава може би данните са фалшифицирани. Но все пак хипотезата за дясната страна обикновено се тества.
Да се върнем на проблема със заровете. Нека изчислим стойността на теста хи-квадрат, като използваме наличните данни.
Сега нека намерим табличната стойност на критерия при 5 степени на свобода ( к) и ниво на значимост 0,05 ( α ).

това е χ 2 0,05; 5 = 11,1.
Нека сравним действителните и табличните стойности. 3.4 ( χ 2) < 11,1 (χ 2 0,05; 5). Изчисленият критерий се оказа по-малък, което означава, че не се отхвърля хипотезата за равенство (съгласуване) на честотите. На фигурата ситуацията изглежда така.

Ако изчислената стойност попада в критичната област, нулевата хипотеза ще бъде отхвърлена.
Би било по-правилно да се изчисли и p-нивото. За да направите това, трябва да намерите най-близката стойност в таблицата за даден брой степени на свобода и да разгледате съответното ниво на значимост. Но това миналия век. Ще използваме персонален компютър, по-специално MS Excel. Excel има няколко функции, свързани с хи-квадрат.

По-долу е дадено кратко описание за тях.
CH2.OBR– критична стойност на критерия при дадена вероятност отляво (както в статистическите таблици)
CH2.OBR.PH– критична стойност на критерия за дадена вероятност отдясно. Функцията по същество дублира предишната. Но тук можете веднага да посочите нивото α , вместо да го извадите от 1. Това е по-удобно, защото в повечето случаи е необходима дясната опашка на разпределението.
CH2.DIST– p-ниво вляво (плътността може да се изчисли).
CH2.DIST.PH– p-ниво вдясно.
CHI2.ТЕСТ– незабавно провежда тест хи-квадрат за два дадени честотни диапазона. Броят на степените на свобода се приема с една по-малък от броя на честотите в колоната (както трябва да бъде), връщайки стойността на p-ниво.
Нека изчислим за нашия експеримент критичната (таблична) стойност за 5 степени на свобода и алфа 0,05. Формула на Excelще изглежда така:
CH2.OBR(0,95;5)
CH2.OBR.PH(0,05;5)
Резултатът ще бъде същият - 11.0705. Това е стойността, която виждаме в таблицата (закръглена до 1 знак след десетичната запетая).
Нека накрая изчислим p-нивото за критерия за 5 степени на свобода χ 2= 3,4. Имаме нужда от вероятността отдясно, така че вземаме функцията с добавяне на HH (дясна опашка)
CH2.DIST.PH(3,4;5) = 0,63857
Това означава, че при 5 степени на свобода вероятността за получаване на стойността на критерия е χ 2= 3,4 и повече е равно на почти 64%. Естествено, хипотезата не се отхвърля (p-нивото е по-голямо от 5%), честотите са в много добро съответствие.
Сега нека проверим хипотезата за съответствие на честотата с помощта на функцията CHI2.TEST.

Без таблици, без тромави изчисления. Като посочим колони с наблюдавани и очаквани честоти като аргументи на функцията, веднага получаваме p-ниво. красота.
Сега си представете, че играете на зарове с подозрителен човек. Разпределението на точките от 1 до 5 остава същото, но той хвърля 26 шестици (общият брой хвърляния става 78).

P-нивото в този случай се оказва 0,003, което е много по-малко от 0,05. Има основателни причини да се съмнявате в валидността на заровете. Ето как изглежда тази вероятност на диаграма за разпределение хи-квадрат.

Самият хи-квадрат тест тук се оказва 17,8, което естествено е по-голямо от табличното (11,1).
Надявам се, че успях да обясня какъв е критерият за съгласие χ 2(хи-квадрат на Пиърсън) и как може да се използва за тестване на статистически хипотези.
И накрая, още веднъж за важно условие! Тестът хи-квадрат работи правилно само когато броят на всички честоти надвишава 50 и минималната очаквана стойност за всяка градация е не по-малка от 5. Ако в която и да е категория очакваната честота е по-малка от 5, но сумата от всички честоти надвишава 50, тогава тази категория се комбинира с най-близката, така че общата им честота да надвишава 5. Ако това не е възможно или сумата от честотите е по-малка от 50, тогава трябва да се използва повече точни методитестване на хипотези. За тях ще говорим друг път.
По-долу има видеоклип за това как да тествате хипотеза в Excel с помощта на теста хи-квадрат.
Министерство на образованието и науката на Руската федерация
Федерална агенция за образование на град Иркутск
Байкал държавен университетикономика и право
Катедра "Информатика и кибернетика".
Хи-квадрат разпределение и неговите приложения
Колмикова Анна Андреевна
Студентка 2-ра година
група ИС-09-1
Иркутск 2010 г
Въведение
1. Хи-квадрат разпределение
Приложение
Заключение
Списък на използваната литература
Въведение
Как се използват подходите, идеите и резултатите от теорията на вероятностите в нашия живот?
Основата е вероятностен модел на реално явление или процес, т.е. математически модел, в който обективните връзки са изразени от гледна точка на теорията на вероятностите. Вероятностите се използват предимно за описание на несигурностите, които трябва да се вземат предвид при вземането на решения. Това се отнася както за нежелани възможности (рискове), така и за привлекателни („щастлив шанс”). Понякога произволността се въвежда умишлено в ситуация, например при теглене на жребий, произволен избор на единици за контрол, провеждане на лотарии или провеждане на потребителски проучвания.
Теорията на вероятностите позволява една вероятност да се използва за изчисляване на други, които представляват интерес за изследователя.
Вероятностният модел на явление или процес е в основата на математическата статистика. Използват се две паралелни серии от понятия – тези, свързани с теорията (вероятностен модел) и тези, свързани с практиката (извадка от резултатите от наблюдението). Например, теоретичната вероятност съответства на честотата, намерена от извадката. Математическото очакване (теоретична серия) съответства на средноаритметичното извадково (практическа серия). По правило характеристиките на извадката са оценки на теоретичните. В същото време количествата, свързани с теоретичните серии, „са в главите на изследователите“, се отнасят до света на идеите (според древногръцкия философ Платон) и не са достъпни за директно измерване. Изследователите разполагат само с примерни данни, с които се опитват да установят свойствата на теоретичен вероятностен модел, който ги интересува.
Защо се нуждаем от вероятностен модел? Факт е, че само с негова помощ свойствата, установени от анализа на конкретна проба, могат да бъдат пренесени върху други проби, както и върху цялата така наречена генерална съвкупност. Терминът "популация" се използва, когато се говори за голяма, но ограничена колекция от изследвани единици. Например за съвкупността от всички жители на Русия или за съвкупността от всички потребители на разтворимо кафе в Москва. Целта на маркетинговите или социологическите проучвания е да прехвърлят твърдения, получени от извадка от стотици или хиляди хора, към популации от няколко милиона души. При контрола на качеството партида от продукти действа като обща съвкупност.
За да се прехвърлят заключения от извадка към по-голяма популация, са необходими някои допускания относно връзката на характеристиките на извадката с характеристиките на тази по-голяма популация. Тези предположения се основават на подходящ вероятностен модел.
Разбира се, възможно е да се обработват примерни данни, без да се използва един или друг вероятностен модел. Например, можете да изчислите примерно средно аритметично, да преброите честотата на изпълнение на определени условия и т.н. Резултатите от изчислението обаче ще се отнасят само до конкретна извадка; прехвърлянето на заключенията, получени с тяхна помощ, към всяка друга популация е неправилно. Тази дейност понякога се нарича „анализ на данни“. В сравнение с вероятностно-статистическите методи, анализът на данни има ограничена образователна стойност.
Така че използването на вероятностни модели, базирани на оценка и тестване на хипотези, използвайки характеристики на извадка, е същността на вероятностно-статистическите методи за вземане на решения.
Хи-квадрат разпределение
С помощта на нормалното разпределение се дефинират три разпределения, които сега често се използват в статистическата обработка на данни. Това са разпределенията на Пиърсън („хи-квадрат“), Студент и Фишер.
Ще се съсредоточим върху разпространението
(„чи – квадрат“). Това разпределение е изследвано за първи път от астронома Ф. Хелмерт през 1876 г. Във връзка с теорията на грешките на Гаус той изучава сумите от квадратите на n независими стандартно нормално разпределени случайни променливи. Карл Пиърсън по-късно нарече тази функция на разпределение „хи-квадрат“. И сега разпределението носи неговото име.Поради тясната си връзка с нормалното разпределение, разпределението χ2 играе важна роля в теорията на вероятностите и математическата статистика. Разпределението χ2 и много други разпределения, които се определят от разпределението χ2 (например разпределението на Стюдънт), описват примерни разпределения на различни функции от нормално разпределени резултати от наблюдение и се използват за конструиране на доверителни интервали и статистически тестове.
Разпределение на Пиърсън
(chi - квадрат) – разпределение на случайна променлива, където X1, X2,..., Xn са нормални независими случайни променливи, като математическото очакване на всяка от тях е нула, а стандартното отклонение е единица.Сбор на квадрати
разпределени по закон
(„чи – квадрат“).В този случай броят на термините, т.е. n се нарича "брой степени на свобода" на разпределението хи-квадрат.С увеличаването на броя на степените на свобода разпределението бавно се доближава до нормалното.
Плътността на това разпределение

И така, разпределението на χ2 зависи от един параметър n – броя на степените на свобода.
Функцията на разпределение χ2 има формата:

ако χ2≥0. (2.7.)
Фигура 1 показва графика на плътността на вероятността и функцията на разпределение χ2 за различни степени на свобода.

Фигура 1Зависимост на плътността на вероятността φ (x) в разпределението χ2 (chi – квадрат) за различен брой степени на свобода.
Моменти на разпределението хи-квадрат:
Разпределението хи-квадрат се използва при оценяване на дисперсията (използване на доверителен интервал), тестване на хипотези за съгласие, хомогенност, независимост, предимно за качествени (категоризирани) променливи, които приемат краен брой стойности, и в много други задачи на анализ на статистически данни .
2. "Хи-квадрат" в задачите на статистическия анализ на данни
Статистическите методи за анализ на данни се използват в почти всички области на човешката дейност. Те се използват винаги, когато е необходимо да се получат и обосноват някакви преценки за група (обекти или субекти) с някаква вътрешна хетерогенност.
Съвременният етап на развитие на статистическите методи може да се брои от 1900 г., когато англичанинът К. Пиърсън основава списанието "Биометрика". Първата третина на ХХ век. премина под знака на параметричната статистика. Методите са изследвани въз основа на анализ на данни от параметрични семейства от разпределения, описани от криви на семейство Пиърсън. Най-популярното беше нормалното разпределение. За проверка на хипотезите са използвани тестовете на Pearson, Student и Fisher. Предложени са методът на максималната вероятност и дисперсионният анализ и са формулирани основните идеи за планиране на експеримента.
Разпределението хи-квадрат е едно от най-широко използваните в статистиката за тестване на статистически хипотези. Въз основа на разпределението хи-квадрат е конструиран един от най-мощните тестове за добро съответствие - хи-квадрат тестът на Pearson.
Критерият за съгласие е критерият за проверка на хипотезата за приетия закон на неизвестно разпределение.
Тестът χ2 (хи-квадрат) се използва за проверка на хипотезата за различни разпределения. Това е неговото достойнство.
Формулата за изчисление на критерия е равна на

където m и m’ са съответно емпирични и теоретични честоти
въпросното разпределение;
n е броят на степените на свобода.
За да проверим, трябва да сравним емпиричните (наблюдавани) и теоретичните (изчислени при предположението за нормално разпределение) честоти.
Ако емпиричните честоти напълно съвпадат с изчислените или очаквани честоти, S (E – T) = 0 и критерият χ2 също ще бъде равен на нула. Ако S (E – T) не е равно на нула, това ще означава несъответствие между изчислените честоти и емпиричните честоти на серията. В такива случаи е необходимо да се оцени значимостта на критерия χ2, който теоретично може да варира от нула до безкрайност. Това се прави чрез сравняване на действително получената стойност на χ2ф с неговата критична стойност (χ2st). Нулевата хипотеза, т.е. предположението, че несъответствието между емпиричните и теоретичните или очакваните честоти е случайно, се опровергава, ако χ2ф е по-голямо или равно на χ2st. за приетото ниво на значимост (a) и броя на степените на свобода (n).
На практика биологични изследванияЧесто е необходимо да се провери една или друга хипотеза, т.е. да се установи до каква степен фактическият материал, получен от експериментатора, потвърждава теоретичното предположение и доколко анализираните данни съвпадат с теоретично очакваните. Възниква задачата да се оцени статистическата разлика между действителните данни и теоретичните очаквания, да се установи в какви случаи и с каква степен на вероятност тази разлика може да се счита за надеждна и, обратно, кога трябва да се счита за незначителна, незначителна, в рамките на случайността. В последния случай се запазва хипотезата, въз основа на която се изчисляват теоретично очакваните данни или показатели. Такава вариационно-статистическа техника за проверка на хипотеза е методът хи-квадрат (χ 2). Тази мярка често се нарича „критерий за съответствие“ или „тест за съответствие на Пиърсън“. С негова помощ можете с различна вероятност да прецените степента на съответствие на емпирично получените данни с теоретично очакваните.
От формална гледна точка се сравняват две вариационни серии, две популации: едната е емпирично разпределение, другата е извадка със същите параметри ( п, М, Си т.н.) е същото като емпиричното, но честотното му разпределение е конструирано в строго съответствие с избрания теоретичен закон (нормален, поасонов, биномен и т.н.), на който се предполага, че се подчинява поведението на изследваната случайна променлива .
IN общ изгледФормулата за критерия за съответствие може да бъде написана по следния начин:
Къде а –действителна честота на наблюденията,
А –теоретично очаквана честота за даден клас.
Нулевата хипотеза предполага, че няма значителни разлики между сравнените разпределения. За да оцените значимостта на тези разлики, трябва да се обърнете към специална таблица с критични стойности на хи-квадрат (Таблица 9 П) и сравняване на изчислената стойност χ 2 с таблицата решете дали емпиричното разпределение се отклонява надеждно или ненадеждно от теоретичното. Така хипотезата за липсата на тези различия ще бъде или опровергана, или оставена в сила. Ако изчислената стойност χ 2 е равно или надвишава таблицата χ ² ( α , df), решават, че емпиричното разпределение се различава значително от теоретичното. Така ще бъде опровергана хипотезата за липсата на тези различия. Ако χ ² < χ ² ( α , df), нулевата хипотеза остава валидна. Общоприето е, че приемливото ниво на значимост α = 0,05, тъй като в този случай има само 5% шанс нулевата хипотеза да е правилна и следователно има достатъчно основание (95%) да се отхвърли.
Определен проблем е правилното определяне на броя на степените на свобода ( df), за които стойностите на критериите са взети от таблицата. За определяне на броя на степените на свобода от общ бройкласове ктрябва да извадите броя на ограниченията (т.е. броя на параметрите, използвани за изчисляване на теоретичните честоти).
В зависимост от вида на разпределението на изследваната характеристика, формулата за изчисляване на броя на степените на свобода ще се промени. За алтернативаразпределения ( к= 2) само един параметър (размер на извадката) е включен в изчисленията, следователно броят на степените на свобода е df= к−1=2−1=1. За полиномФормулата за разпределение е подобна: df= к−1. За проверка на съответствието вариационна серияразпространение Поасонвече се използват два параметъра - размер на извадката и средна стойност (числово съвпадаща с дисперсията); брой степени на свобода df= к−2. При проверка на последователността на емпиричното разпределение опцията нормалноили биномСъгласно закона, броят на степените на свобода се приема като броя на действителните класове минус три условия за конструиране на сериите - размер на извадката, средна стойност и дисперсия, df= к−3. Веднага си струва да се отбележи, че критерият χ² работи само за проби обем от поне 25 варианта, а честотите на отделните класове трябва да бъдат не по-ниска от 4.
Първо, ние илюстрираме използването на теста хи-квадрат, като използваме пример за анализ алтернативна променливост. В един експеримент за изследване на наследствеността на доматите са открити 3629 червени и 1176 жълти плода. Теоретичното съотношение на честотите за разделяне на знаците във второто хибридно поколение трябва да бъде 3:1 (75% към 25%). Прилага ли се? С други думи, тази проба взета ли е от популация, в която честотното съотношение е 3:1 или 0,75:0,25?
Нека създадем таблица (Таблица 4), попълвайки стойностите на емпиричните честоти и резултатите от изчисляването на теоретичните честоти по формулата:
A = n∙p,
Къде стр– теоретични честоти (части от вариант от този тип),
n –размер на извадката.
например, А 2 = n∙p 2 = 4805∙0.25 = 1201.25 ≈ 1201.
Разгледайте приложението вMSEXCELХи-квадрат тест на Pearson за тестване на прости хипотези.
След получаване на експериментални данни (т.е. когато има такива проба) обикновено се прави избор на закон за разпределение, който най-добре описва случайната променлива, представена от дадено вземане на проби. Проверката колко добре експерименталните данни са описани от избрания теоретичен закон за разпределение се извършва с помощта на критерии за споразумение. Нулева хипотеза, обикновено има хипотеза за равенството на разпределението на случайна променлива с някакъв теоретичен закон.
Нека първо да разгледаме приложението Тест за съответствие на Pearson X 2 (хи-квадрат)по отношение на прости хипотези (параметрите на теоретичното разпределение се считат за известни). Тогава - , когато е посочена само формата на разпределението и параметрите на това разпределение и стойността статистика X 2 се оценяват/изчисляват въз основа на същите мостри.
Забележка: В англоезичната литература процедурата за кандидатстване Тест за съответствие на Pearson X 2 има име Тест за съответствие на хи-квадрат.
Нека си припомним процедурата за проверка на хипотези:
- въз основа на мостристойността се изчислява статистика, което съответства на вида на тестваната хипотеза. Например за използвани t- статистика(ако не е известно);
- подчинени на истината нулева хипотеза, разпространението на това статистикае известно и може да се използва за изчисляване на вероятностите (например за t- статистикаТова);
- изчислено въз основа на мостризначение статистикав сравнение с критичната стойност за дадена стойност ();
- нулева хипотезаотхвърли ако стойност статистикапо-голяма от критичната (или ако вероятността да получите тази стойност статистика() по-малко ниво на значимост, което е еквивалентен подход).
Нека изпълним проверка на хипотезиза различни дистрибуции.
Дискретен случай
Да предположим, че двама души играят на зарове. Всеки играч има свой собствен комплект зарове. Играчите се редуват да хвърлят 3 зара наведнъж. Всеки рунд се печели от този, който хвърли най-много шестици наведнъж. Резултатите се записват. Един от играчите, след 100 рунда, имаше подозрение, че заровете на опонента му са асиметрични, т.к. често печели (често хвърля шестици). Той реши да анализира колко вероятен е такъв брой вражески резултати.
Забележка: Защото Има 3 кубчета, след което можете да хвърлите 0 наведнъж; 1; 2 или 3 шестици, т.е. една случайна променлива може да приеме 4 стойности.
От теорията на вероятностите знаем, че ако заровете са симетрични, тогава вероятността за получаване на шестици се подчинява. Следователно, след 100 кръга, честотите на шестиците могат да бъдат изчислени с помощта на формулата
=BINOM.DIST(A7;3;1/6;FALSE)*100
Формулата предполага, че в клетката A7 съдържа съответния брой шестици, хвърлени в един кръг.
Забележка: Изчисленията са дадени в примерен файл на Дискретния лист.
За сравнение наблюдавани(Наблюдавано) и теоретични честоти(Очаквано) удобен за използване.

Ако наблюдаваните честоти се отклоняват значително от теоретичното разпределение, нулева хипотезаотносно разпределението на случайна променлива според теоретичен закон трябва да се отхвърли. Тоест, ако заровете на противника са асиметрични, тогава наблюдаваните честоти ще бъдат „значително различни“ от биномно разпределение.
В нашия случай на пръв поглед честотите са доста близки и без изчисления е трудно да се направи еднозначно заключение. Приложимо Тест за съответствие на Pearson X 2, така че вместо субективното твърдение „съществено различен“, което може да се направи въз основа на сравнение хистограми, използвайте математически правилно твърдение.
Използваме факта, че поради закон големи числа наблюдавана честота (Наблюдавано) с увеличаване на обема мостри n клони към вероятността, съответстваща на теоретичния закон (в нашия случай, биномен закон). В нашия случай размерът на извадката n е 100.
Нека се запознаем тест статистика, което означаваме с X 2:

където O l е наблюдаваната честота на събития, при които случайната променлива е приела определени приемливи стойности, E l е съответната теоретична честота (очаквана). L е броят на стойностите, които една случайна променлива може да приеме (в нашия случай е 4).
Както се вижда от формулата, това статистикае мярка за близостта на наблюдаваните честоти до теоретичните, т.е. може да се използва за оценка на "разстоянията" между тези честоти. Ако сумата от тези „разстояния“ е „твърде голяма“, тогава тези честоти са „значително различни“. Ясно е, че ако нашият куб е симетричен (т.е. приложим биномен закон), тогава вероятността сумата от „разстояния“ да бъде „твърде голяма“ ще бъде малка. За да изчислим тази вероятност, трябва да знаем разпределението статистика X 2 ( статистика X 2, изчислено въз основа на случаен принцип мостри, следователно е случайна променлива и следователно има своя собствена разпределение на вероятностите).
От многоизмерния аналог Интегрална теорема на Моавр-Лапласизвестно е, че за n->∞ нашата случайна променлива X 2 е асимптотично с L - 1 степени на свобода.
Така че, ако изчислената стойност статистика X 2 (сумата от „разстоянията“ между честотите) ще бъде по-голяма от определена гранична стойност, тогава ще имаме причина да отхвърлим нулева хипотеза. Същото като проверката параметрични хипотези, граничната стойност се задава чрез ниво на значимост. Ако вероятността статистиката X2 да приеме стойност, по-малка или равна на изчислената ( стр-смисъл), ще бъде по-малко ниво на значимост, Това нулева хипотезамогат да бъдат отхвърлени.
В нашия случай статистическата стойност е 22,757. Вероятността статистиката X2 да приеме стойност, по-голяма или равна на 22,757, е много малка (0,000045) и може да се изчисли с помощта на формулите
=CHI2.DIST.PH(22,757,4-1)или
=CHI2.TEST(Наблюдаван; Очакван)
Забележка: Функцията CHI2.TEST() е специално проектирана да тества връзката между две категорични променливи (вижте).
Вероятност 0,000045 е значително по-малка от обикновено ниво на значимост 0,05. Така че играчът има всички основания да подозира опонента си в нечестност ( нулева хипотезанеговата честност е отречена).

При използване критерий X 2необходимо е да се гарантира, че обемът мостри n е достатъчно голямо, в противен случай приближението на разпределението няма да е валидно статистика X 2. Обикновено се смята, че за това е достатъчно наблюдаваните честоти (наблюдавани) да са по-големи от 5. Ако това не е така, тогава малките честоти се комбинират в една или се добавят към други честоти и на комбинираната стойност се присвоява обща вероятност и съответно броят на степените на свобода се намалява Х 2 разпределения.
За да се подобри качеството на приложението критерий X 2(), е необходимо да се намалят интервалите на разделяне (увеличете L и съответно увеличете броя степени на свобода), обаче, това се предотвратява от ограничението за броя на наблюденията, включени във всеки интервал (db>5).
Непрекъснат случай
Тест за съответствие на Pearson X 2 може да се приложи и при .
Нека разгледаме определен проба, състоящ се от 200 стойности. Нулева хипотезазаявява, че пробанаправени от .
Забележка: Случайни променливи в примерен файл на непрекъснатия листгенерирани с помощта на формулата =NORM.ST.INV(RAND()). Следователно нови ценности мострисе генерират при всяко преизчисляване на листа.
Може да се оцени визуално дали съществуващият набор от данни е подходящ.

Както се вижда от диаграмата, примерните стойности се вписват доста добре по правата линия. Въпреки това, както във за проверка на хипотезиприложимо Pearson X 2 тест за съответствие.
За да направим това, разделяме диапазона на промяна на случайната променлива на интервали със стъпка 0,5. Нека изчислим наблюдаваните и теоретичните честоти. Ние изчисляваме наблюдаваните честоти с помощта на функцията FREQUENCY(), а теоретичните с помощта на функцията NORM.ST.DIST().
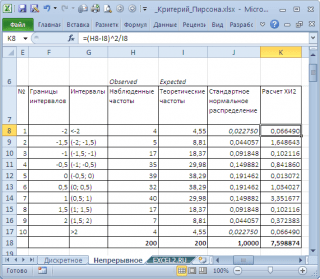
Забележка: Същото като за дискретен случай, необходимо е да се гарантира, че пробабеше доста голям и интервалът включваше >5 стойности.
Нека изчислим статистиката X2 и я сравним с критичната стойност за дадена ниво на значимост(0,05). защото разделихме диапазона на промяна на случайна променлива на 10 интервала, тогава броят на степените на свобода е 9. Критичната стойност може да се изчисли с помощта на формулата
=CHI2.OBR.PH(0,05;9) или
=CHI2.OBR(1-0,05;9)
Диаграмата по-горе показва, че статистическата стойност е 8,19, което е значително по-високо критична стойност – нулева хипотезане се отхвърля.
По-долу е къде пробапридоби невероятно значение и се основава на критерии Съгласие на Pearson X 2нулевата хипотеза беше отхвърлена (въпреки че произволните стойности бяха генерирани с помощта на формулата =NORM.ST.INV(RAND()), осигуряване пробаот стандартно нормално разпределение).

Нулева хипотезаотхвърлени, въпреки че визуално данните са разположени доста близо до права линия.
Да вземем и за пример пробаот U(-3; 3). В този случай дори от графиката е очевидно, че нулева хипотезаследва да се отхвърли.

Критерий Съгласие на Pearson X 2също потвърждава това нулева хипотезаследва да се отхвърли.
Публикации по темата
-
.jpg) Безопасна защита на растенията от болести и неприятели през юли и август
Безопасна защита на растенията от болести и неприятели през юли и август
Нашите предци също са знаели, че добрата реколта зависи не само от упорита и отговорна работа, но и от фазите на луната. Разберете и сте благосклонни...
-
 Рекордната зърнена реколта ще доведе до дефлация Жътвата на зърно в Руската федерация
Рекордната зърнена реколта ще доведе до дефлация Жътвата на зърно в Руската федерация
18.07.2017 - 21:03 Новини на Беларус. Започна масовата жътва на зърнени култури в югозападната част на страната, съобщиха от "24 часа" на...